先週から今週にかけてAIに関するニュース(Gemini Pro・Chat with RTX・Sora)が飛び込んできて、再びLLM・生成AIの話題が沸騰中みたいです。
別方面ではありますが、まだまだAIへの投資と進化は止まらなさそうです。手元のPCで動く日が来るかもしれないと思うと楽しみですね✨
エッジAIだとラズパイ5の日本上陸も重大トピックの1つでしょう。
3倍速いと言われるCPUとPCIeのコネクタ実装によって新しい使い方ができるようですね。
今回は このRaspberryPi ROCK5内蔵のNPUで遊ぼう思います🙃(おい
ROCK5とは?
ROCK5はシングルボードコンピュータを開発・製造しているRadxaのボードです。AとBがあり、私が使っているのはRaspberryPi Bに形状が似たAタイプです。
RaspberryPi 5 ModelBと形状が似ており、他の製品についてもほとんどRaspberryPiのCPU以外は全部パクリと言ってもいいでしょう。
ROCK5にはARM-CPU(Cortex-A76とCortex-A55のbig.LITTLE構成)が搭載されており、m.2が差せるところもあります。また、ラズパイらしい配置のUSBコネクタやGPIO・カメラコネクタも備えているので、もう実質RaspberryPi5と行ったところでしょう。
実は1ヶ月ほど前に入手して、CPU性能まわりを軽く調べていました。
Ubuntu-Desktopのリッチなグラフィックスも余裕で動かすくらいのGPU性能とCPU8コアの物量があるので、CPU性能だけに目を向ければラズパイはおろか、周辺のミニPCともいい勝負ができるでしょう。
内蔵AIアクセラレーション(NPU)は?
CPUは別にROCK5 (RK3588) 以外にもいくらでも選択肢があるわけで、ここまで読む限りではRaspberryPiでもよくね?となるかもしれません。
ここからはハードウェアアクセラレーションも軽く試してみることにします。
RockchipのRK3588には、最大6TOPsのAI推論用のチップ(NPU)が搭載されています。
AI推論といえばGPU (NVIDIA-CUDA・cuDNN) の使用が浮かびますが、NPUはAI推論に必要な機能に絞っているため、小型・低消費電力でありながら高速に処理することができます。とにかく小型・省電力なので、最近ではスマートフォンやノートPCにNPUを搭載するモデルも増えているようです。
外付けデバイス無し・2万弱でこの性能は嬉しいですね。
YOLOXのアクセラレーション
Rockchipのnpu (rknpu)を使用したAI推論例はrknn_model_zooに揃っています。
私が公開しているリポジトリにYOLOX-ROSというものがありますが、現時点ではx86前提のものが多いので、新たにrknpu向けに機能を追加したいなと思っています。
なお、今回の記事で紹介する実装については既にGitHubに上げています。
2種類以上同時に動かすと(多分設定の不具合で)プロセスが落ちる場合があるので、API操作が間違っているなどあればissue・PRお待ちしています🙇
モデル変換
Rockchipのnpuでモデルを動かす場合はNPU向けの量子化(拡張子:.rknn)が必要です
airockchip/rknn_model_zooのyolox/python/convert.py でonnxモデルを変換します。
モデル構造がNPU向けに最適化されているので Megvii-BaseDetection/YOLOX で配布されているonnxは使用しないでください。
x86-64環境にAI用変換ツール(rknn-tookit2)の環境を構築した上でonnxを変換スクリプトで変換します。
python3 convert.py <path to yolox_s.onnx> rk3588
ROS 2との統合
とりあえずROS 2と統合していろいろなデバイスでお試しできるようにしました。
YOLOXのrknn実装はC言語で書かれておりrknn_model_zooにもOpenCVのC実装が入っていますが、これを使うとなぜかうまく実行できなかったので、毎度OpenCVのMat型からimage_buffer型に変換しています。
↓ 該当箇所
cv::Mat3b YOLOX::image_buffer_to_mat3b(image_buffer_t* image_buffer) { cv::Mat3b mat(image_buffer->height, image_buffer->width); memcpy(mat.data, image_buffer->virt_addr, image_buffer->size); return mat; } image_buffer_t YOLOX::mat3b_to_image_buffer(cv::Mat3b* mat) { image_buffer_t image_buffer; memset(&image_buffer, 0, sizeof(image_buffer_t)); image_buffer.width = mat->cols; image_buffer.height = mat->rows; image_buffer.width_stride = mat->cols; image_buffer.height_stride = mat->rows; image_buffer.format = IMAGE_FORMAT_RGB888; image_buffer.size = mat->cols * mat->rows * 3; image_buffer.virt_addr = (unsigned char*)malloc(image_buffer.size); memcpy(image_buffer.virt_addr, mat->data, image_buffer.size); return image_buffer; }
パフォーマンスを大きく落としてはいないので今のところはこれでよしとしています。
依存環境
OSはこちらを使用しました。
使用するボードを確認してimgを選択してください。SDカードやemmc、SSDなどに焼きます。
emmcやSSDだと設定を色々いじる必要がありそうです。
「SDカード不安定」と言われていますが、私は気にせずに使ってます。
Ubuntu22.04をインストールしたら ros-humble-desktopをインストールします。
Ubuntu (Debian packages) — ROS 2 Documentation: Humble documentation
librealsenseを使いたい場合は、Ar-Ray-code/installerのREADME_Raspbian内にある 2.54.2:v4l2 のdebパッケージをダウンロードしてインストールします。
cd wget https://s3.ap-northeast-1.wasabisys.com/download-raw/dpkg/librealsense/debian/bookworm/librealsense-v4l2-backend-app-bookworm-2-54-2-arm64.deb -O ./librealsense.deb # 2.54.2 (v4l2) / bookworm sudo apt install ./librealsense.deb sudo curl https://raw.githubusercontent.com/IntelRealSense/librealsense/master/config/99-realsense-libusb.rules --output /etc/udev/rules.d/99-realsense-libusb.rules sudo udevadm control --reload-rules sudo udevadm trigger
realsense_rosを使用する場合はlibrealsenseに対応したバージョンのブランチを切って後述の yolox_rk3588_ros と一緒にビルドします。
ビルド方法
mkdir -p ~/ros2_ws/src cd ~/ros2_ws/src git clone https://github.com/Ar-Ray-code/yolox_rk3588_ros.git bash yolox_rk3588_cpp/install.sh # パスワード入力 cd .. colcon build
install.shはlibrknnrt.soとlibrga.soを/usr/local/libにコピーするためのコマンドです。
実行方法
事前にimage_publisher など画像送信トピックを起動します。
モデルは yolox_s.rknn とします。
export TARGET_RKNN=./yolox_s.rknn
source ~/ros2_ws/install/setup.bash
taskset -c 4,5,6,7 ros2 run yolox_rk3588_ros yolox_rk3588_ros_node --ros-args -p model_path:=${TARGET_RKNN}
ros2 run の前に付いてる taskset -c 4,5,6,7 は、タスクを指定したCPUコア番号で使用することを指定しています。
0~3番目はCortex-A55、4~7番目がCortex-A76に割り当てられているため、後者の方がちょっとスピードが速いです。
あと、pub-subどちらも同じコアに割り当ててください。異なると動かなくなったりパフォーマンスが落ちることがあります。 (pub側が0~3のコアだったらsub側も0~3のコア)
以下、実行時の様子
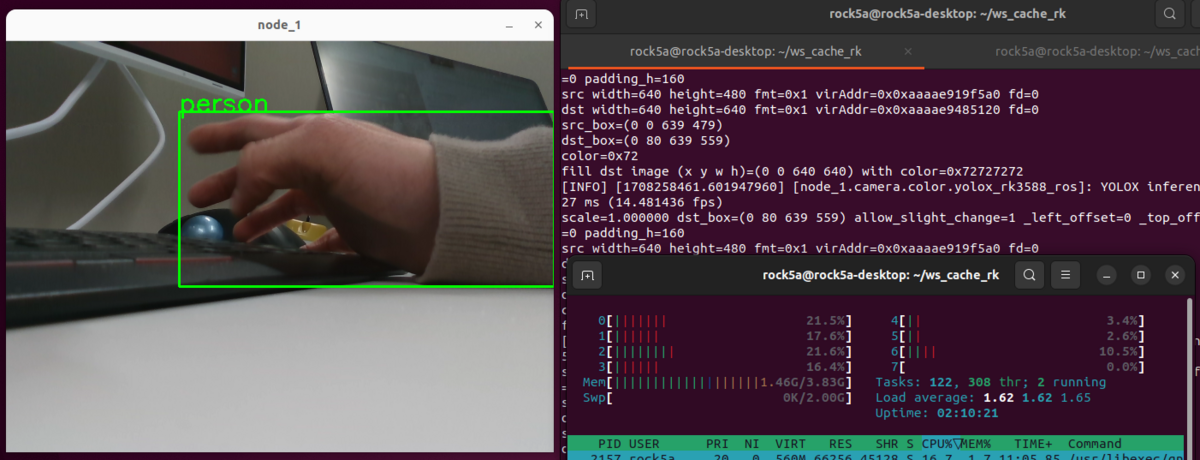
パフォーマンスはYOLOX-Mで12~14fps程度 (preprocess・postprocess含む) です。参考元のリポジトリの通りの性能が出ていることは確認できました。
量子化の影響か、tinyやnanoなど416x416の入力の推論だとガクッと精度が落ちてしまうので、sやm推奨です。
電力は測っていないのですが、RaspberryPi用の15WのACアダプタでも動いています。
まとめ
ビルドの過程でいろいろ試行錯誤したので、情報がまとまっておらず雑に書いていますが、省電力AIチップ何かないかなーと探している人には結構選択肢に入るのかなと思い書きました。
本当はハードウェアエンコードやカメラも試して1話完結させたかったですが、今後もちまちまと書いていこうと思います。