今日は、YOLOv3-tinyを使ったボルト・ナット検出を通じてYOLOv3-tinyの学習のやり方の備忘録を書きます。
YOLOv3-tinyは他のYOLOと比べてとても速いです。今回は講習用にボルト・ナットの検出器を作成してみました。
環境
さまざま記事でYOLOv3の環境構築について言及されているので、このページは特に示しませんが、YOLOv3の本家実装を使っています。YOLOv4でも同様に動作すると思います。
全体的な流れ
下の図は学習コマンド実行までの大まかなフローです。順を追って説明します。

1. 画像の撮影
最も大事な工程は画像の撮影です。とにかく画像は多く、画質やコントラストなどがいいものを撮ったほうがいいです。きれいな画像は加工でぼかしたりノイズを乗せたりできますが、画質の粗い画像は高画質にできないので、この段階が良くないとそのあとの処理で苦労すると思います。(もしかしたら、あえてその手法をとって性能を上げる術があるのかもしれませんが、私はモチベが下がると思います。)
ここでは、ボルト・ナット・ワッシャー・スプリングワッシャーの4つの分類器を作成するために、画像を収集します。今回は、お手軽画像処理ということで、iPhoneの4K品質で6枚撮影しました。また、検証のために、一回も学習を行わないボルト画像を用意します。


2.画像の加工・選定
この作業は任意ですが、私は、撮影した画像6枚から10枚の画像を作成することで、60枚のデータセットを作成しました。GIMPを用いて切り抜いています。目的によっては何かしらの前処理を行うことがあります。

3.画像のアノテーション
とても面倒で退屈な作業です。おそらく、需要の増加によって5~10年経つ頃に新たなギグワークとして若者の注目を集めると(個人的に)思います。

さまざまなツールがありますが、私はYolo_Labelを使っています。GUIのデザインがいいのでお勧めです。
4.水増し
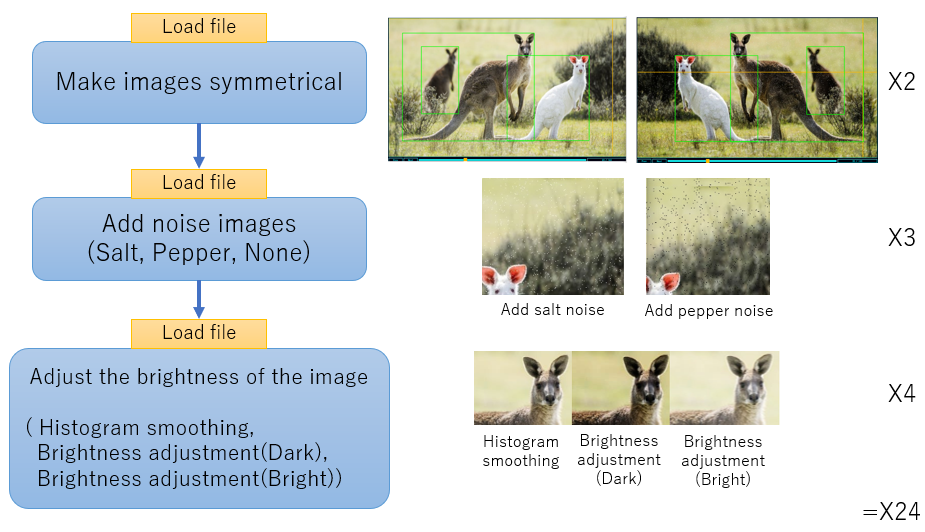
アノテーション工程が終われば、おそらくデータセットフォルダには画像とテキストファイルのセットが画像枚数分だけあると思います。ただし、機械学習は60枚では全く学習になりません。(水増ししても足りませんが…)そこで、水増しを行います。左右反転・ノイズ付加・輝度調整をそれぞれ行い、24倍の水増しをします。自動で行うプログラムをYOLOのtextファイルも一緒に水増しを行うプログラムを作った - えいあーる・れいの技術日記で以前作成していたので、これを使って水増しを行います。1枚ずつ増やしていくので、そこそこ時間がかかります…
5.設定ファイルの作成(1):cfgファイルの作成
yolov3.cfgに代わるファイルを作成します。今回は、YOLOv3-tinyなので、yolov3-tiny.cfgをコピーして、次の箇所を変更します。
- batchの項目:batch=1をbatch=16に変更
- [YOLO]のブロック内について(2か所)
- classesの項目:classes=4に変更
- [YOLO]のブロックの一つ前のブロックにある項目について(2か所)
- filtersの項目:filters=3x(classes+5)の計算式より、filters=27に変更
batchを増やした結果、メモリエラーが発生する場合はsubdivisionを増やすか、batchを減らすかをしましょう。batchを落とすと性能が低下し、subdivisionを増やすと学習時間が延びます。
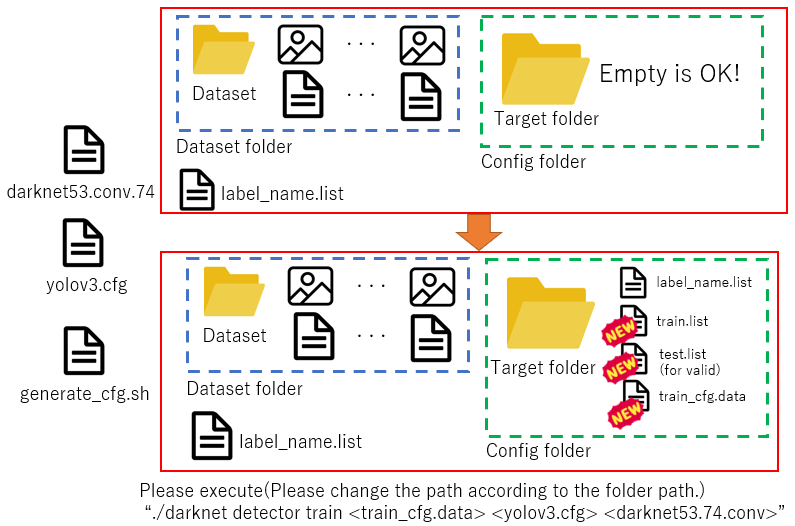
6.設定ファイルの作成(2):学習・テストデータ分類他
これは自動化しました。 YOLO v3の学習時に面倒なパス通しをShellで自動化! - えいあーる・れいの技術日記プログラムはGithubにあります。
学習
6が終わると、設定フォルダにパスの情報があり、アノテーションも全て終わっていることになります。あとは、初期重みとなるdarknet53.conv.74をダウンロードして、
$ <darknet_path>/darknet detector train <darknet_path>/train_cfg.data <your cfg file> <darknet53.conv.74's path>とコマンドを入力します。ファイルのパスは特に指定されていませんが、問題がないなら、全て設定フォルダに入れておくと、分かりやすいでしょう。
学習は半日~1日かかります。損失のグラフは下の通りです。今回は、3万回学習させました。

学習モデルの検証
学習が終わったら、backupディレクトリに入っている重みを使って認識できているかチェックしましょう。今回は、数値を正確に出すわけでもないので、ざっくりと調べていきます。
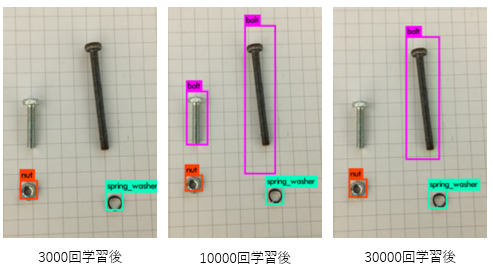
未使用の画像の対する結果は下の画像の通りです。3000回だと、十分な学習ができておらず、ボルトが正しく認識されていません。10000回の時点ではすべての物体を正しく認識しているようです。しかし、30000回になると、逆にボルトが認識されなくなりました。これは、ある長さのボルトに対して過剰に適応する「過学習」の状態になったと考えられます。水増し後を含めても学習枚数が十分でないことを表しています。
学習に使用したデータでも、誤検出が起こる場合もあります。撮影距離の変更や、そもそも長さに応じてクラス分けをし直すなどの検討をしたほうがいいかもしれませんね。
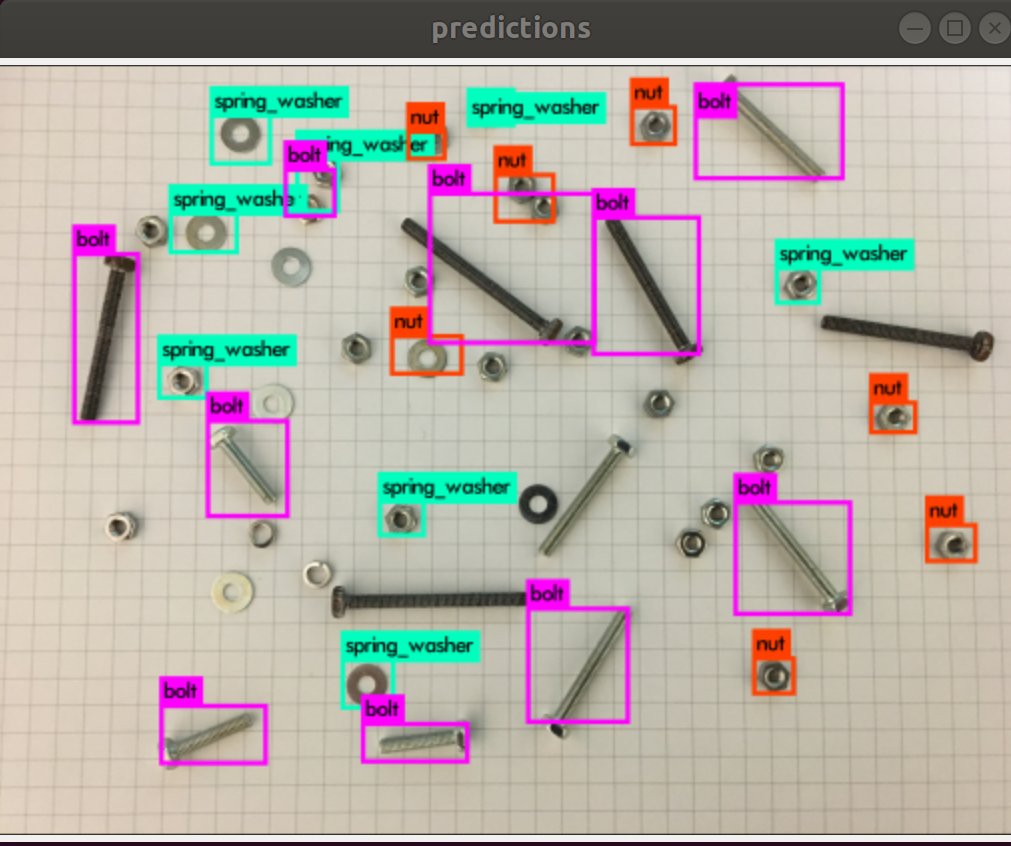
実環境により近い状況ならどうでしょうか?Webカメラで撮影してみました。

これまた誤検出や未検出が多発しています…さまざまな背景や処理を施したほうが良いかもしれませんね。
まとめ
今回はYOLOv3-tinyの学習の流れを簡単に説明しました。特定の物体の検出をする分にはお手軽にできると思うので、ぜひ試してみてください。